[模型推理] Inference From Scratch: Tensor Parallel / 推理中的张量并行
文章含 AI 量:< 10%。AI 主要负责润色。 代码含 AI 量:< 5%。
Parallelism / 并行计算
由于 Scaling Law 带来的涌现效应,现代模型的嵌入维度、层数、隐藏层维度、上下文窗口长度都越来越大,由此带来的计算量和显存需求也越来越大。并行处理是 Scaling Law 得以持续成立的关键,也是大模型越来越强大的基础。如今的模型参数动辄几百B甚至上T,比如 DeepSeek-V4-Pro 参数量高达 1.6T,而 Nvidia B300 单卡显存仅 288 GB,即使采用 FP4 精度也需要接近 800 GB 的显存才能在单卡上跑起来。并行计算,既要解决超大模型能不能跑起来的问题,也要解决模型跑得快不快的问题。
在模型并行计算上,Megatron-LM 是经典之作(Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism),推荐阅读,本文介绍的方法正是来自这篇论文。另外,通过本文的介绍,也可以看到集合通信是如何在并行计算中被使用的。
Data Parallel vs Model Parallel / 数据并行和模型并行
数据并行和模型并行是两种典型的并行方法:
- 数据并行(Data Parallel,DP):把模型复制到不同的 GPU 上,每个 GPU 运行完整的模型副本。这是一种典型的水平扩展方法。
- 模型并行:把模型拆分到不同的 GPU 上,每个 GPU 运行模型的一部分。模型并行又分为两种典型的方法:
- 流水线并行(Pipeline Parallel,PP):把模型的不同 Decoder 层拆分到不同的 GPU 上运行。
- 张量并行(Tensor Parallel,TP):把模型的单个算子拆分到不同的 GPU 上运行。
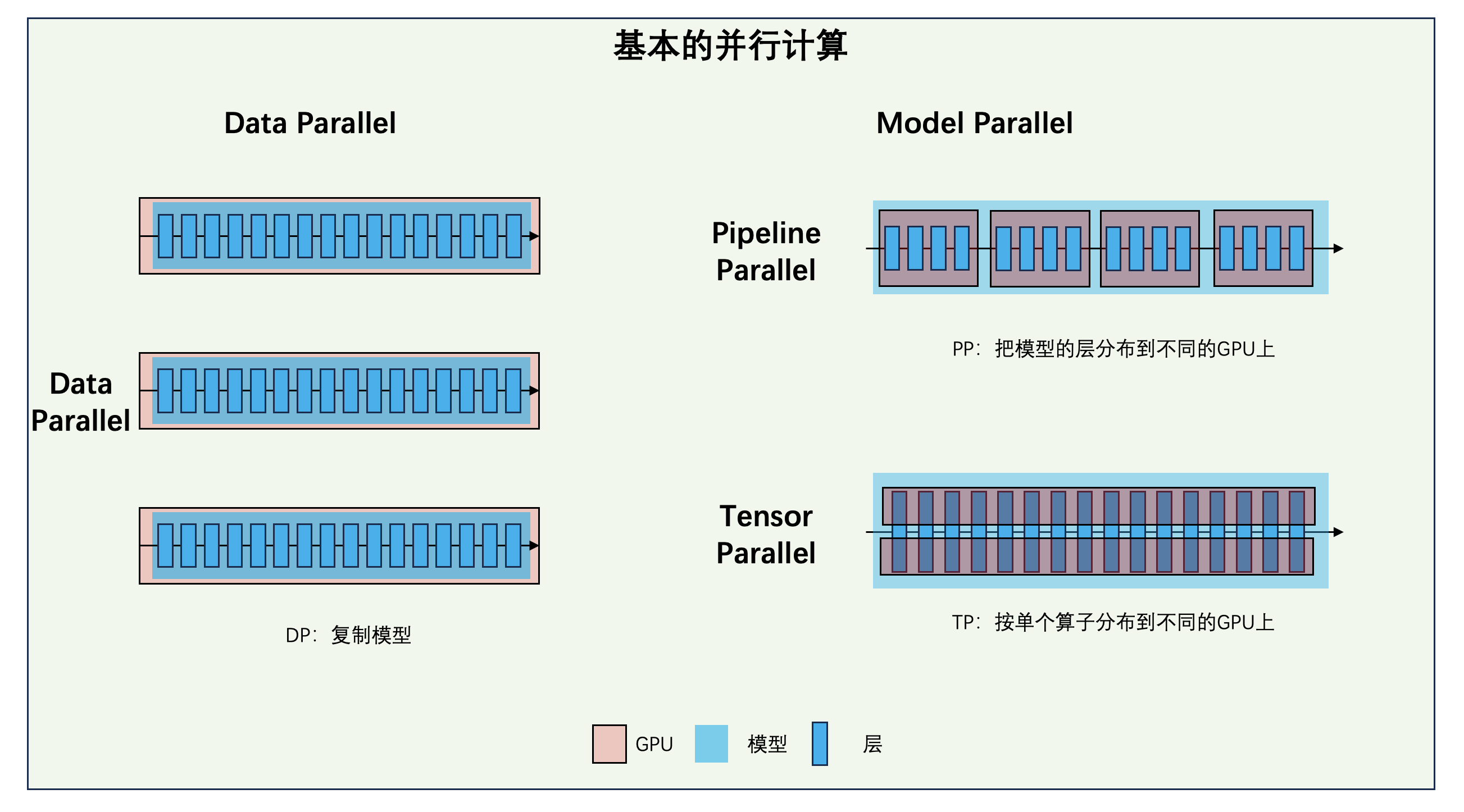
三种并行方法各有优劣,适用场景也不同:
数据并行(DP):
- 优点:实现简单,每个 GPU 独立运行完整模型副本,推理时几乎无通信开销;适合高吞吐场景,可线性扩展 batch size。
- 缺点:每个 GPU 需要存储完整模型参数和优化器状态,无法解决单卡放不下模型的问题;扩展性受限于单卡显存。
- 适用场景:模型较小、batch size 大的推理场景(如在线服务高并发);训练中常与 TP/PP 组合使用。
流水线并行(PP):
- 优点:每层参数只存储在一个 GPU 上,显著降低单卡显存压力;通信仅发生在层间边界,通信频率低。
- 缺点:存在"气泡"(Bubble)问题——前一个 GPU 计算时后续 GPU 空闲等待,GPU 利用率不高;层间计算量不均时负载均衡困难。
- 适用场景:模型层数多、单层参数量大的场景;通常与 TP 结合使用(如 Megatron-LM 的 PTD-P 方案)。
张量并行(TP):
- 优点:单层内的计算和参数都被拆分,单卡显存压力最小;计算效率高,GPU 利用率高。
- 缺点:每层都需要 all-reduce 通信,通信频繁,对 GPU 间带宽要求极高;通常只能在单机内使用(依赖 NVLink 等高带宽互联)。
- 适用场景:单层参数或计算量过大、单卡无法承载时;需要高带宽互联(NVLink/NVSwitch);常与 PP 和 DP 组合构成 3D 并行。
DP 和 PP 都是通用的方法,在计算机科学领域早已被广泛使用:
- CPU:流水线和多发射是典型的并行方法,分别对应 PP 和 DP。
- 网络处理:网络高速数据报文处理中,Run To Complete 和 Pipeline 也是典型的方法,分别对应 DP 和 PP。
而 TP 本质上是一种面向代数计算领域的特定并行方法,因此需要首先介绍它的原理和具体方法。
Tensor Parallel / 张量并行
在 [模型推理] Inference From Scratch: KV Cache - Part1 / 推理中的 KV Cache - 原理篇 这篇文章曾经介绍过,大模型中的操作可以分为这三类:1)矩阵乘法;2)Row-wise 操作;3)Element-wise 操作。矩阵乘法是大模型中最主要的操作,注意力机制中的 计算Q/K/V、注意力分数、注意力加权求和,多层感知机的 升维、降维,都是矩阵操作。在张量并行下,矩阵运算是如何被并行计算的呢?
考虑这个矩阵乘法:$ Y = X*W+B $,其中 $ X $ 输入是 $ [t, m] $ 的矩阵($ X $ 代表文本输入,有 $ t $ 个 token,每个 token 是长度为 $ m $ 的嵌入向量),$ W $ 权重是 $ [m, n] $ 的矩阵,$ B $ 偏置是长度为 $ [n] $ 的数组。本文的讨论均使用大部分实现中常用的行向量。
下面这个矩阵乘法的示意图,各个操作数的大小都标在图上。这里为了符合大部分教科书上神经网络结构从左到右、输入输出垂直分布的习惯,$ X $、$ Y $ 的示意图对行和列进行了交换:
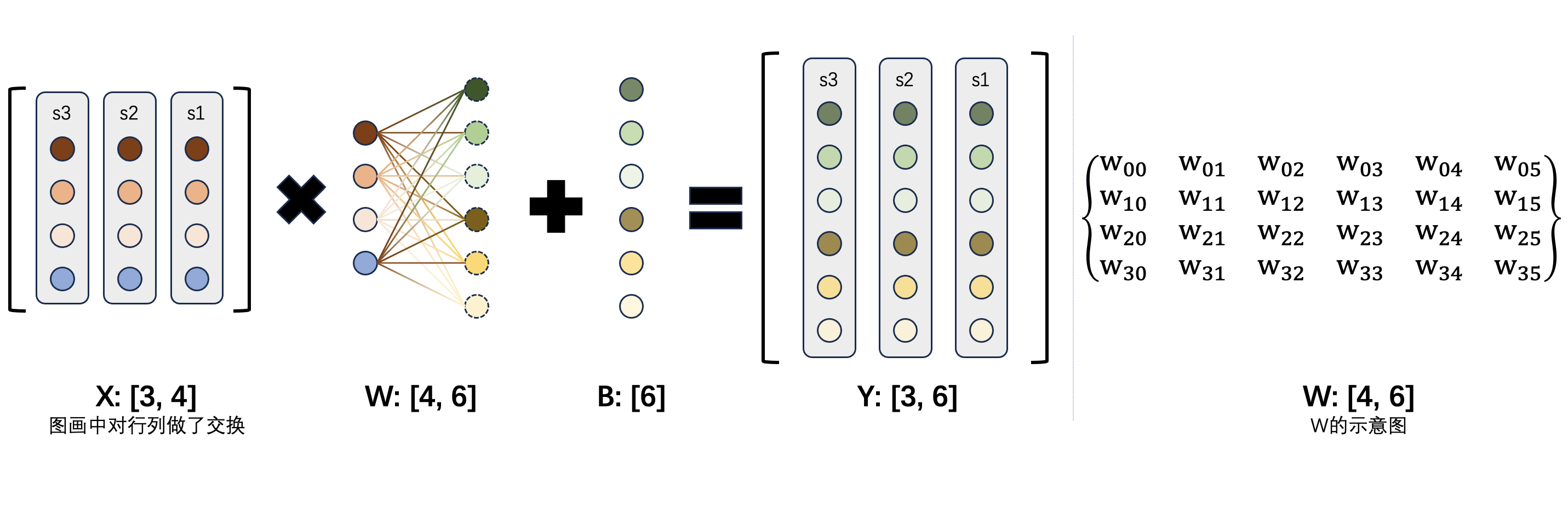
Column-wise Parallel GEMM / 按列切分进行矩阵的并行计算
我们对矩阵的权重 $ W $ 按列的方向进行切分,那么并行计算的示意图如下:
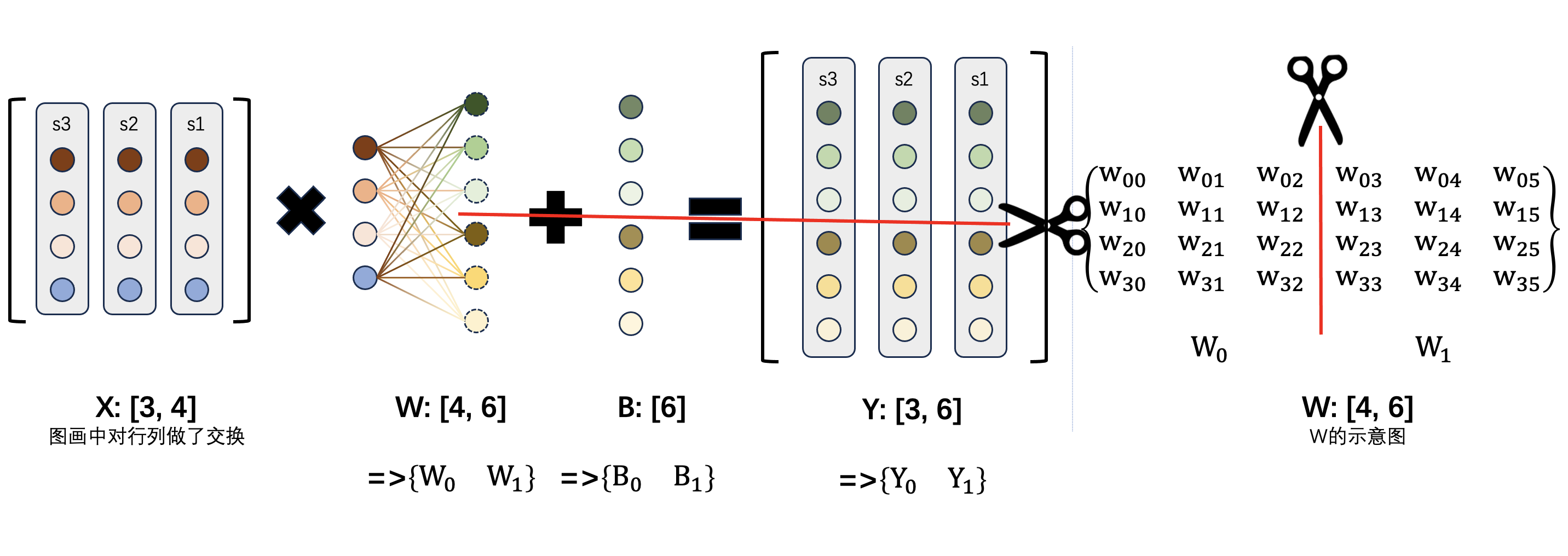
权重的列代表什么?让我们回想一下 MLP 的架构,权重的每一个列代表一个输出特征。因此,按列切分代表了按输出特征进行了切分,每个 GPU 计算一部分输出特征。如上图中,使用 2 个 GPU 进行并行计算,第 0 个 GPU 拿到前 3 列的权重,输出每个样本的前 3 个特征值;依次类推,第 1 个 GPU 拿到后 3 列的权重,输出每个样本的 3 个特征值。我们要怎么拿到完整的结果呢?需要把这两个矩阵按列方向进行拼接。
这个方法的特点是:
- 将 $ W $ 和 $ B $ 都按照列的维度进行切分(把 $ B $ 看成是一个 $ [1, n] $ 的矩阵),每个 GPU 拿到的是 1 / k 的参数。
- 在每个 GPU 上输入的 $ X $ 是完整的。
- 每个 GPU 计算出的结果中,属于该 GPU 的特征值都是完整的(最终值),但不包含所有维度的特征值。如果后面接的是 Element-wise 操作,可以直接由该 GPU 继续完成。实际上,$ + B $ 就是典型的 Element-wise 操作。
- $ k $ 是并行的 GPU 数,第 $ i $ 个 GPU 计算出来的是 $ [i*n/k, (i+1)*n/k) $ 这些维度的特征值。
- 把每个 GPU 的矩阵按列方向拼接,最后每个样本仍是 $ n/k * k = n $ 维的特征。
- 需要的集合通信操作是 all_gather,即在所有 GPU 上收集各 GPU 的输出 $ Y_i $,并进行矩阵拼接。
Row-wise Parallel / 按行切分进行矩阵的并行计算
我们对矩阵的权重 $ W $ 按行的方向进行切分,那么并行计算的示意图如下:
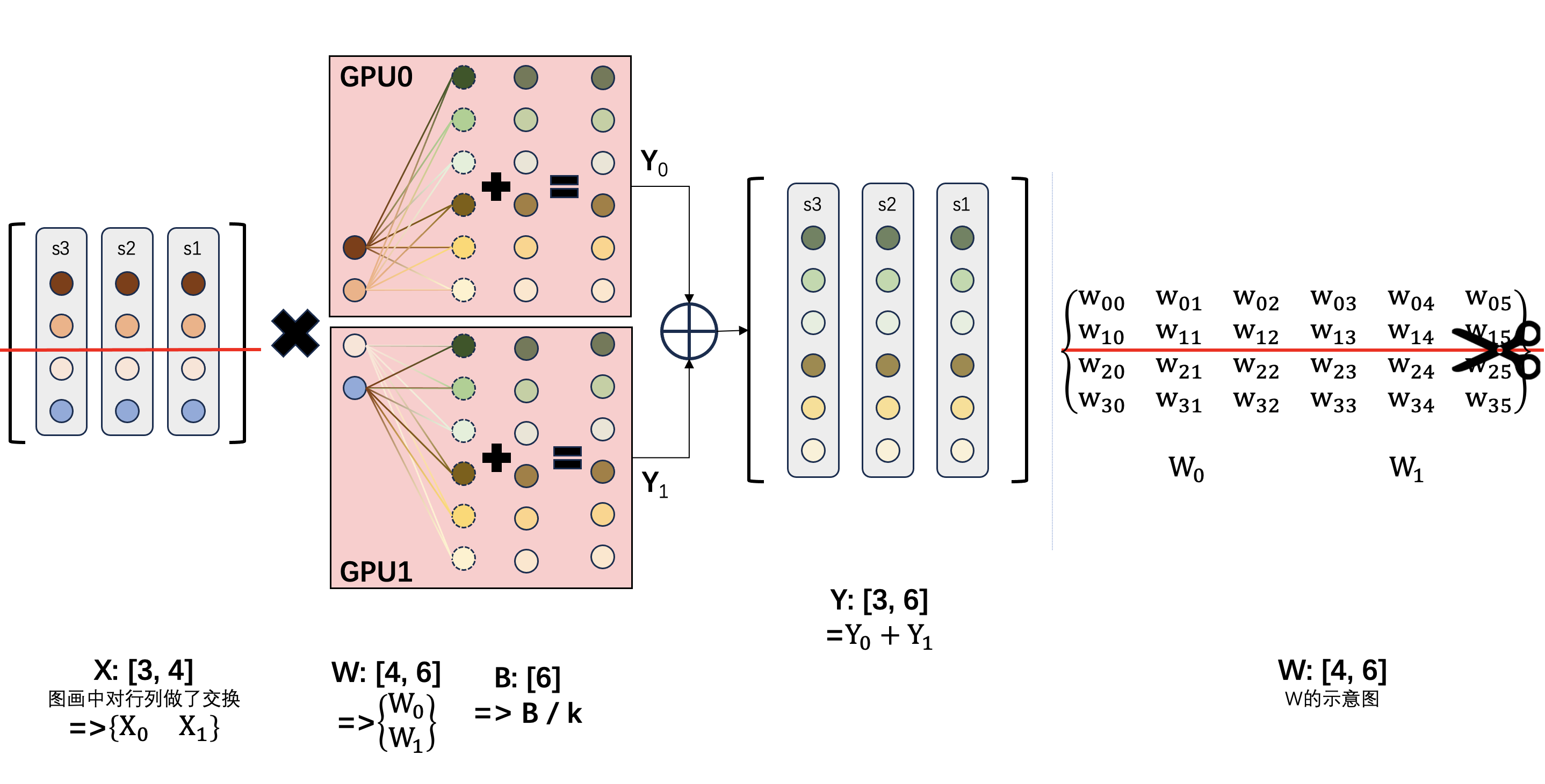
权重的行代表什么?代表输入特征的每个维度对该列输出特征的比例系数。沿着行切分后,每个 GPU 只有部分输入维度的比例系数,这意味着两点:1)输入也需要按列进行切分(而按列切分 W 的方法不需要切分输入);2)每个 GPU 上都无法独立得到完整的输出特征。
这个方法的特点是:
- 将 $ W $ 按照行的维度进行切分,每个 GPU 拿到的是 1 / k 的 W 参数。
- 每个 GPU 上的输入 $ X $ 需要按列方向进行切分。
- $ B $ 参数有两种处理方式:1)在合并前,每个特征上加上 $ B $,但这样会把 $ B $ 加 k 次,因此需要先将原始偏置除以 k,即 $ B / k $;2)在合并后直接加 $ B $。不管哪种方式,每个 GPU 上都有长度为 $ n $ 的 $ B $ 参数。结合上一条,这种方式下每个 GPU 的参数量略大,不过由于 $ B $ 是一维向量,通常可以忽略这种差异。
- 每个 GPU 上的结果包含所有维度的特征值,矩阵形状为 $ [t, n] $,与最终结果的形状一致。但每个特征值都只有部分分量,结果还不完整(还不是最终特征值)。后面可以接线性变换,但不能接非线性操作。
- 把每个 GPU 得到的结果按元素相加,得到最终的计算结果。
- 需要的集合通信操作是 all_reduce,这正是上一步所要求的语义。
其它操作的 TP
除了矩阵运算外,其它操作,比如 Embedding 查找、LayerNorm、RMSNorm,也可以进行按行切分的并行计算。不过这些操作的参数量和计算量都很小,通常可以忽略。
TP的实现
介绍完 TP 的基本原理后,我们结合 GPT2 的结构和代码,看看如何在 LLM 中实现 TP。首先,跟串行计算的版本相比,变与不变各是什么?不变:保持层与层之间的结果不变,无论是数据的形状还是它的值(这里先不考虑计算误差)。也就是说,在下图的红线位置来观察,即使是 TP 中的一个 worker GPU,在这里观察到的也都是完整正确的数据。变:在层内部采用多 GPU 并行计算。
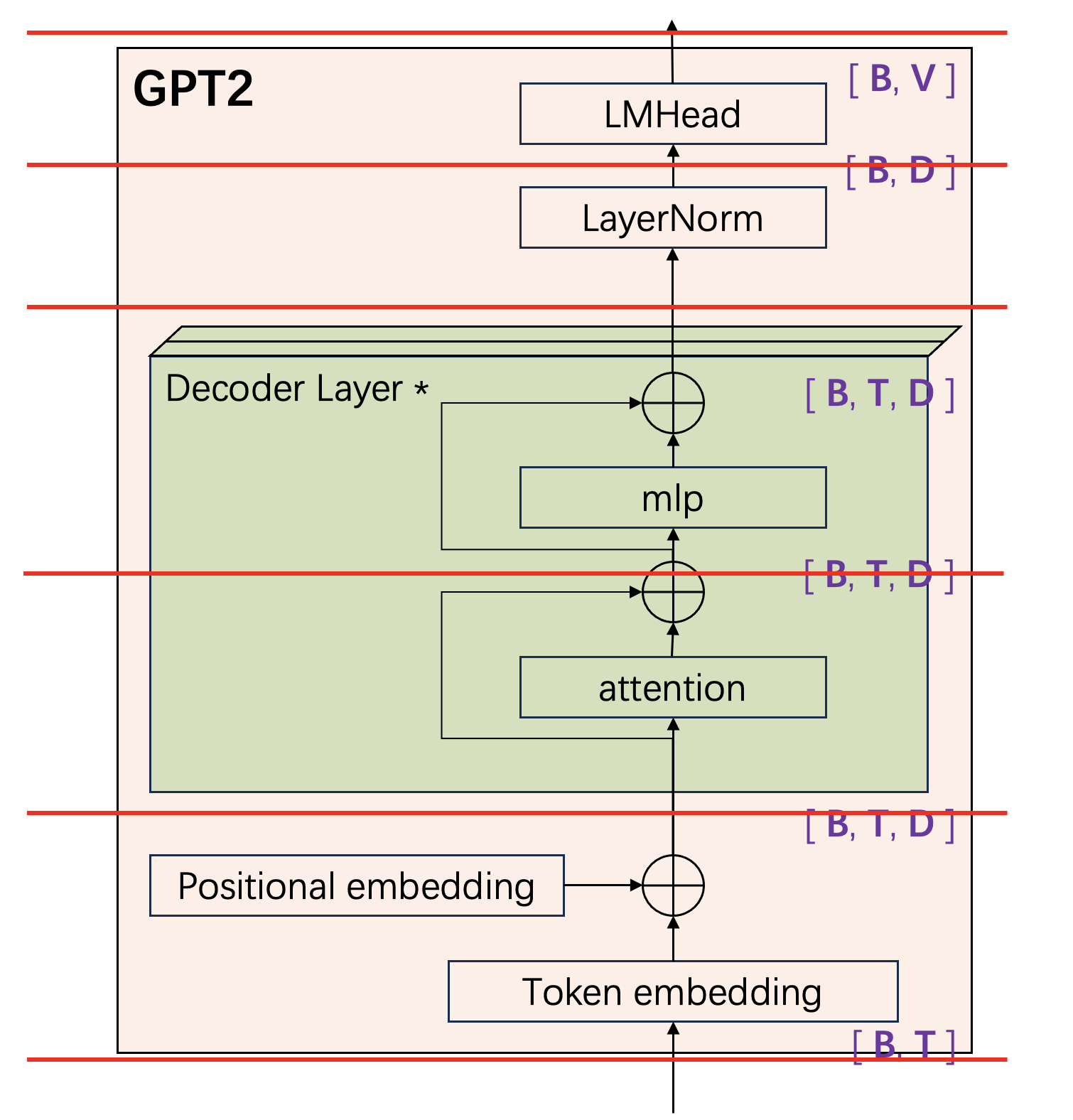
world 模块
Link:world.py。
world 模块提供了 TP 并行计算的基础信息:
WORLD_SIZE: 整数,并行计算的 GPU 数量,满足条件WORLD_SIZE >= 1,值为 1 时表示没有 TP 并行。这也是本文中的 $ k $ 参数。RANK: 整数,当前 GPU 的序号,满足条件RANK >= 0 and RANK < WORLD_SIZE,这也是本文中的 $ i $ 参数。tensor_split(tensor: torch.Tensor, dim: int) -> torch.Tensor: 把输入的张量在指定的维度上平均切分成WORLD_SIZE份,并返回属于当前 RANK 的那一份。all_gather(tensor: torch.Tensor, dim=-1) -> torch.Tensor:把所有 GPU 上的输入张量在 dim 维度上按照RANK顺序拼接在一起,满足条件output.shape[dim] = input.shape[dim] * WORLD_SIZE。all_reduce(tensor: torch.Tensor, op=dist.ReduceOp.SUM): 把所有 GPU 上的输入张量做 Element-wise 的求和,或者 op 指定的操作(比如求最大、最小)。这是一个原地操作,直接更新输入的张量。broadcast(tensor: torch.Tensor, src=0): 把RANK=src的张量广播到其它所有的 GPU 上。
all_gather / all_reduce / broadcast 等集合操作的典型特点是,所有的参与者在操作结束后,得到相同的输出。
Decoder
Megatron-LM 论文中的图太经典了,以至于我实在认为必须直接引用。
MLP
MLP 是一个 线性层 + 激活函数 + 线性层 的组合,套用前面矩阵乘法的 Column-wise Parallel + Row-wise Parallel 这个模式特别顺手。
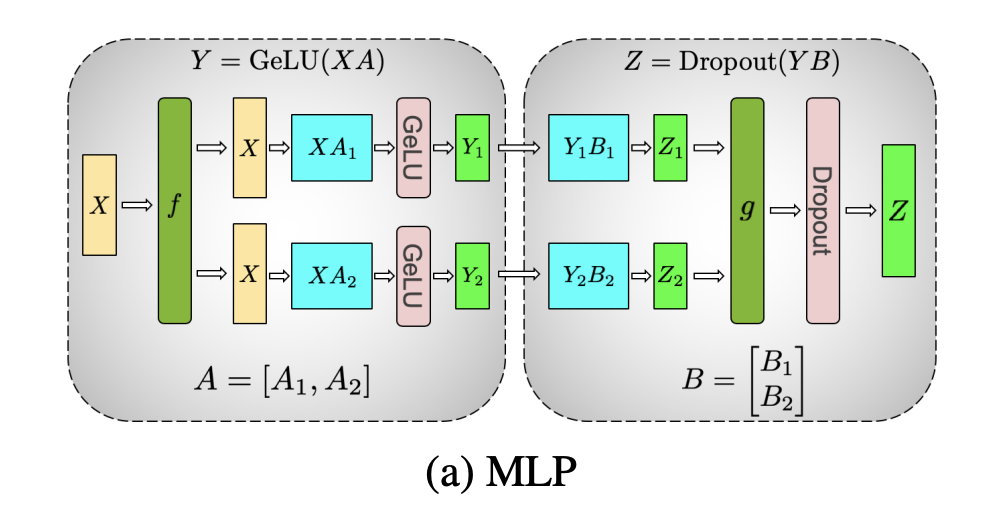
图中的 f/g 是合并结果的操作,f 用于训练中的反向计算,在推理中可以认为空操作。g 用于推理的正向计算,对应集合通信的 all_reduce。
说明:
- 第一个线性层按列切分,每个 GPU 拥有部分维度的特征值。
- 激活函数是 Element-wise 的操作,每个 GPU 上拥有部分维度的特征完整值,可以直接应用激活函数。
- 第二个线性层按行切分——注意,第一步中输出已按列切分,天然匹配了第二步的输入要求。最终计算得到每个特征值的部分分量。
- 最后使用集合通信 all_reduce,把所有 GPU 得到的值相加,得到完整的结果。
Attention
Attention 中操作比较多:QKV映射 + 多头拆分 + 注意力分数计算 + 因果掩码 + softmax + 注意力加权求和 + 多头合并 + 输出投影。如果我们按照前面的 TP 原则,对每一个操作都施加以上方法,从正确性上来说也是对的。但这样做的通信开销会很大。实际上,因为注意力头之间是独立的,我们直接把整个头的操作都放在同一个 GPU 上执行,是更简单、更高效的方法。
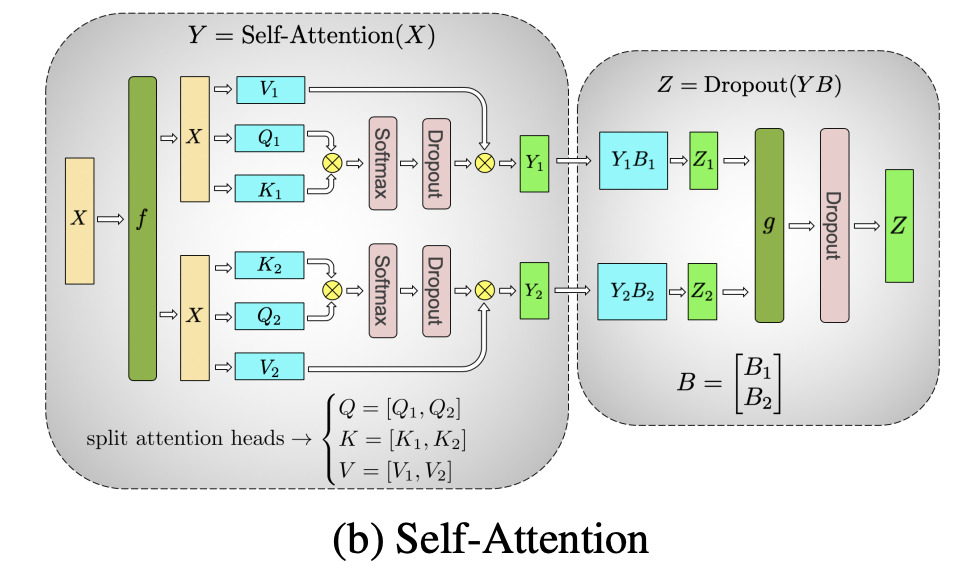
图中的 f/g 是合并结果的操作,f 用于训练中的反向计算,在推理中可以认为空操作。g 用于推理的正向计算,对应集合通信的 all_reduce。
说明:
- 左框是注意力层的主体部分,包含了
输入按头切分 -> ( QKV映射 + 多头拆分 + 注意力分数计算 + 因果掩码 + softmax + 注意力加权求和 ) + 多头合并的过程,其中括号部分都是单头内的操作。 - 右框是注意力层的
输出投影部分。 - 模型中有 H 个注意力头,每个 GPU 处理 $ H / k $ 个注意力头,其中 $ k = WORLD_SIZE $。
- 左图中 Q 按列切分为 $ Q_1, Q_2, ..., Q_k $,每个 $ Q_i $ 包含 $ H / k $ 个头的维度信息。K / V 同理。
- 左图中输出的 $ Y_1, Y_2, ..., Y_k $ 沿列方向拼接即可得到原始 $ Y $,不过这个拼接并未实际发生——天然沿列切分的数据被直接送入
输出投影部分。 - 右图中,由于输入已沿列切分,输出投影的矩阵乘法采用行切分的方式进行并行计算,得到每个特征值的部分分量。
- $ g $ 函数执行
all_reduce操作,把所有 GPU 得到的值相加,得到完整的结果。
从大的结构上来看,Attention 层本身也是先做 Column-wise Parallel,再做 Row-wise Parallel,和 MLP 层的思想一样。
代码实现
Link:gpt2_model.py。
先看 DecoderLayer::attention() 的修改,主体结构并没有大的变化,仅仅是在 多头拆分 和 多头合并 的部分,将头数从原来的 H 修改为 H / k:
@@ -111,12 +157,12 @@ class DecoderLayer():
scale = torch.rsqrt(torch.tensor([self.d_model / self.H], dtype=x.dtype, device=x.device))
# split q, k, v
- q, k, v = qkv_merged.split(self.d_model, dim=-1)
- q = q.reshape((-1, seq_len, self.H, self.d_model // self.H))
+ q, k, v = qkv_merged.split(self.d_model // self.H * self.H_local, dim=-1)
+ q = q.reshape((-1, seq_len, self.H_local, self.d_model // self.H))
q = q.transpose(-2, -3)
- k = k.reshape((-1, seq_len, self.H, self.d_model // self.H))
+ k = k.reshape((-1, seq_len, self.H_local, self.d_model // self.H))
k = k.transpose(-2, -3)
- v = v.reshape((-1, seq_len, self.H, self.d_model // self.H))
+ v = v.reshape((-1, seq_len, self.H_local, self.d_model // self.H))
v = v.transpose(-2, -3)
# k_cache: [B, H, cached_len, d_k]
@@ -140,7 +186,7 @@ class DecoderLayer():
scores = torch.matmul(scores, v)
# merges back
x = scores.transpose(-2, -3)
- x = x.reshape((-1, seq_len, self.d_model))
+ x = x.reshape((-1, seq_len, self.d_model // self.H * self.H_local))
x = torch.matmul(x, self.attn_proj_weight) + self.attn_proj_bias
return x
而 DecoderLayer::mlp() 函数本身没有变化。实现这一切的关键在于 DecoderLayer::load_state_dict() 和 DecoderLayer::forward()。
DecoderLayer::forward():
@@ -156,9 +202,13 @@ class DecoderLayer():
def forward(self, x: torch.Tensor, kvcache_entry: Optional[llm_types.KVCacheEntry], use_cache: bool = True) -> torch.Tensor:
residual = x
a = self.attention(x, kvcache_entry, use_cache)
+ if world.WORLD_SIZE > 1:
+ world.all_reduce(a)
x = a + residual
residual = x
m = self.mlp(x)
+ if world.WORLD_SIZE > 1:
+ world.all_reduce(m)
x = m + residual
return x
第二个 all_reduce 实现了 MLP 小节介绍的特征值加和部分。第一个 all_reduce 实现了 Attention 小节介绍的特征值加和部分。
DecoderLayer::load_state_dict():
@@ -85,6 +111,26 @@ class DecoderLayer():
self.c_proj_bias = state_dict.pop('mlp.c_proj.bias')
# 剩下一个 attn.bias 没啥用
attn_mask_bias = state_dict.pop('attn.bias')
+
+ if world.WORLD_SIZE > 1:
+ # Attention
+ attn_q_weight, attn_k_weight, attn_v_weight = self.attn_weight.split(self.d_model, dim=-1)
+ attn_q_weight = world.tensor_split(attn_q_weight, dim=-1)
+ attn_k_weight = world.tensor_split(attn_k_weight, dim=-1)
+ attn_v_weight = world.tensor_split(attn_v_weight, dim=-1)
+ self.attn_weight = torch.cat([attn_q_weight, attn_k_weight, attn_v_weight], dim=-1)
+ attn_q_bias, attn_k_bias, attn_v_bias = self.attn_bias.split(self.d_model, dim=-1)
+ attn_q_bias = world.tensor_split(attn_q_bias, dim=-1)
+ attn_k_bias = world.tensor_split(attn_k_bias, dim=-1)
+ attn_v_bias = world.tensor_split(attn_v_bias, dim=-1)
+ self.attn_bias = torch.cat([attn_q_bias, attn_k_bias, attn_v_bias], dim=-1)
+ self.attn_proj_weight = world.tensor_split(self.attn_proj_weight, dim=-2)
+ self.attn_proj_bias.div_(world.WORLD_SIZE)
+ # MLP
+ self.c_fc_weight = world.tensor_split(self.c_fc_weight, dim=-1)
+ self.c_fc_bias = world.tensor_split(self.c_fc_bias, dim=-1)
+ self.c_proj_weight = world.tensor_split(self.c_proj_weight, dim=-2)
+ self.c_proj_bias.div_(world.WORLD_SIZE)
MLP 部分的参数切分,就是先做列切分(对 c_fc_weight / c_fc_bias 的处理,dim=-1),再做行切分(对 c_proj_weight 的处理,dim=-2;bias 平均分)。Attention 层也类似,稍微复杂的是 GPT2 的 Q/K/V 矩阵是合并在一起的,所以需要先把权重按 Q/K/V 拆开,各自做切分,最后再合并回去。
Embedding
Embedding 的参数量不是特别大,以 GPT2 为例,Embedding 参数量约为 38M,加速效果并不明显。因此这一层是否需要并行拆分,值得权衡 —— 让每个 GPU 上都有完整的 Embedding 权重,也完全可以接受。代码中,只是为了展示 Embedding 的 TP 并行,采用了 按列维度切分 + all_gather 合并 的方式实现。
代码实现
读到这里,相信大家对这个修改的原理都非常清楚了:
@@ -28,6 +29,10 @@ class Embed():
self.wte_weight = state_dict.pop('wte.weight')
self.wpe_weight = state_dict.pop('wpe.weight')
+ if world.WORLD_SIZE > 1:
+ self.wte_weight = world.tensor_split(self.wte_weight, dim=-1)
+ self.wpe_weight = world.tensor_split(self.wpe_weight, dim=-1)
+
def to(self, device: torch.device):
self.device = device
self.wte_weight = self.wte_weight.to(device)
@@ -38,6 +43,8 @@ class Embed():
seq_len = input_ids.shape[-1]
x = self.wte_weight[input_ids]
x = x + self.wpe_weight[offset : offset + seq_len, :]
+ if world.WORLD_SIZE > 1:
+ x = world.all_gather(x)
return x
LM Head
LM Head 是一个矩阵乘法,它做 TP 并行的必要性同样较低:LM Head 只使用最后一个 token 的特征值作为输入,计算量并不高。代码中,同样为了展示 TP 并行方案,也做了实现。
唯一的小麻烦是,LM Head 的列(分词器的词元数量,GPT2 中是 50257)无法被 WORLD_SIZE 整除。处理这个问题比较简洁的方式是 padding —— 将它补齐到 WORLD_SIZE 的倍数,计算完成后再把 padding 部分删除。这个问题的根源是 Byte-Pair Encoding 和 Weight Tying 的设计,后续的模型设计可以规避这一点,让模型本身对并行更友好。
代码实现
直接上代码:
@@ -49,11 +56,24 @@ class LMHead():
def load_state_dict(self, state_dict):
self.weight = state_dict.pop('wte.weight').T
+ if world.WORLD_SIZE > 1:
+ self.vocab_padsize = (self.vocab_size + world.WORLD_SIZE - 1) // world.WORLD_SIZE * world.WORLD_SIZE - self.vocab_size
+ if self.vocab_padsize > 0:
+ pad_shape = list(self.weight.shape)
+ pad_shape[-1] = self.vocab_padsize
+ pad_tensor = torch.zeros(*pad_shape, dtype=self.weight.dtype, device=self.weight.device)
+ self.weight = torch.cat([self.weight, pad_tensor], dim=-1)
+ self.weight = world.tensor_split(self.weight, dim=-1)
+
def to(self, device: torch.device):
self.weight = self.weight.to(device)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = torch.matmul(x, self.weight)
+ if world.WORLD_SIZE > 1:
+ x = world.all_gather(x, dim=-1)
+ if self.vocab_padsize > 0:
+ x = x.split([self.vocab_size, self.vocab_padsize], dim=-1)[0]
return x
支持部分
KV Cache 同样拆分
在 KV Cache 实现篇 中介绍过 KVCacheEntry 的结构。原来每个 GPU 上需要放置全部注意力头的 KV Cache,现在因为注意力头已经按 GPU 切分,KV Cache 同样进行拆分。
这里可以体会到,通过 TP + KV Cache,GPU 的显存在模型参数和 KV Cache 两个维度上都得到了水平扩展。
代码实现
@@ -173,6 +223,12 @@ class Chatgpt2Model(llm_types.Model):
self.context_window = config['n_ctx']
self.layernorm_eps = config.get('layer_norm_epsilon', 1e-05)
+ if world.WORLD_SIZE > 1:
+ assert self.H % world.WORLD_SIZE == 0
+ self.H_local = self.H // world.WORLD_SIZE
+ else:
+ self.H_local = self.H
+
self.decoders = []
for layer_id in range(self.L):
self.decoders.append(
@@ -220,25 +276,36 @@ class Chatgpt2Model(llm_types.Model):
allocate a kvcache tensor for batch.
dim0's size must be 2, [0] will be k-cache, [1] will be v-cache
'''
- cache_shape = (2, self.L, batch_size, self.H, seq_len, self.d_model // self.H)
+ cache_shape = (2, self.L, batch_size, self.H_local, seq_len, self.d_model // self.H)
cache = torch.zeros(cache_shape, dtype=self.embed.wte_weight.dtype, device=self.device)
return cache
怎么在多个 GPU 上运行模型?
怎么在多个 GPU 上运行程序?这似乎是个简单的问题,当然可以用 torch.multiprocessing 来跑多个进程,不过手工管理进程比较繁琐。我们可以用 torchrun 启动多个进程,torch 会把 WORLD_SIZE 和 RANK 通过环境变量传递给每个进程,并监视它们的运行:
torchrun --nproc-per-node 2 ./main.py ./models.cache/gpt2-small "A B C D E F G A B C D E F G A B C D E F G A B C D E F G "
要注意的是,不要让每个 worker 都打印结果输出,我们只需要让 RANK 等于 0 的 worker 输出结果:
@@ -73,7 +81,7 @@ def generate(model_instance: llm_types.Model, tokenizer: llm_types.Tokenizer, sa
@click.option("--truncate-to", type=int, help="truncate the prompt to this length, default is -1 (no truncation)", default=-1)
@click.option("--disable-kvcache", is_flag=True, help="disable kvcache", default=False)
@click.option("--debug", is_flag=True, default=False)
-def run(model_path: str, prompt: str, output_tokens: int, temperature: float, topk: int, topp: float, device: str, truncate_to: int, disable_kvcache: bool, debug: bool):
+def run(model_path: str, prompt: str, output_tokens: int, temperature: float, topk: int, topp: float, device: str, backend: str, truncate_to: int, disable_kvcache: bool, debug: bool):
global in_debug_mode
in_debug_mode = debug
utils.setup_logging("INFO" if not debug else "DEBUG")
@@ -88,8 +96,9 @@ def run(model_path: str, prompt: str, output_tokens: int, temperature: float, to
prompt = f.read()
device_name = device
- device = llm_loader.select_device(device_name)
+ device = world.select_device(device_name)
logging.info(f"Using device: {device}")
+ world.initialize(device, backend)
path = pathlib.Path(model_path)
model_instance, tokenizer = llm_loader.load(path, device)
@@ -101,13 +110,15 @@ def run(model_path: str, prompt: str, output_tokens: int, temperature: float, to
try:
while True:
newtext = next(output_stream)
- print(newtext, end='', flush=True)
+ if world.RANK == 0:
+ print(newtext, end='', flush=True)
except StopIteration as e:
if e.value:
generated_tokens, stop_reason = e.value
print()
end_time = time.time()
- logging.info(f"generated_tokens={generated_tokens}, stop_reason={stop_reason}, used time={end_time - begin_time}, TPS={generated_tokens / (end_time - begin_time)}")
+ if world.RANK == 0:
+ logging.info(f"generated_tokens={generated_tokens}, stop_reason={stop_reason}, used time={end_time - begin_time}, TPS={generated_tokens / (end_time - begin_time)}")
还有一个小问题,worker 如何终止?
这似乎不是什么大问题,每个 worker 各自做采样,当它们输出 EOS 或者达到最大长度,同时退出就可以了。达到最大长度同时退出,这没问题。但是输出 EOS 退出,这个判断不能由每个 worker 独立采样来决定,因为每次采样是概率性的。除非保证每个 worker 的随机数生成器的行为完全同步(这也可以控制),否则无法保证一致。
为了解决这个问题,我们让 RANK=0 的 worker 做采样,其它 worker 等待这个采样结果即可。
@@ -44,7 +47,11 @@ def generate(model_instance: llm_types.Model, tokenizer: llm_types.Tokenizer, sa
stop_reason = None
while True:
logits = model_instance.forward(input_ids, kvcache_entry=kvcache_entry, use_cache=not disable_kvcache)
- next_token_ids = sampler.sample(logits)
+ if world.RANK == 0:
+ next_token_ids = sampler.sample(logits).to(torch.int)
+ else:
+ next_token_ids = torch.zeros( (1, 1), dtype=torch.int, device=logits.device)
+ world.broadcast(next_token_ids, src=0)
next_token_ids_cpu = next_token_ids.to("cpu")
if next_token_ids_cpu[0].item() == model_instance.eos_token_id:
stop_reason = "finish"
Stay Curious
本文介绍了 TP 的基本原理及其在 GPT2 中的实现,还有许多值得深入探索的方向:
- 3D 并行:TP、PP、DP 如何组合使用(如 Megatron-LM 提出的 PTD-P 方案),在不同维度上实现计算和显存的均衡。
- 集合通信的底层实现:all-reduce、all-gather 等操作在 NVLink、NVSwitch、InfiniBand 等硬件上是如何高效实现的(Ring AllReduce、Tree AllReduce 等算法)。
- 序列并行(Sequence Parallel):在 TP 的基础上,将 LayerNorm 和 Dropout 等操作也沿序列维度切分,进一步降低显存占用。
- 专家并行(Expert Parallel):在 MoE 模型中,如何将不同专家分布到不同 GPU 上,并结合 TP 实现高效推理。