[模型推理] GPT2 Inference With KV Cache - Part2 / 推理中的 KV Cache - 实现篇
文章含 AI 量:< 10%。AI 主要负责润色。 代码含 AI 量:< 5%。
代码面前,了无秘密。只有亲手重写一遍,才能看清藏在细节里的魔鬼。
代码:https://github.com/solofox/gpt2,branch:kvcache。
这篇讲 KV Cache 的实现。原理篇在这里。
设计
在动手写代码之前,先讨论两个关键的设计决策。
谁管理 KV Cache?
KV Cache 的管理可以在两个层次进行:
- 模型(Model)层:模型内部自行维护 cache,对调用方透明。
- 引擎(Engine)层:由模型的调用方(推理引擎)统一分配和管理 cache,模型只负责使用和更新。
在模型层管理的优势是调用方简单,不需要感知 KV Cache 的存在。但劣势也很明显——模型变成了有状态的实体。更重要的是,KV Cache 是现代 LLM serving 的核心数据结构,后续的 Continuous Batching、Chunked Prefill、PagedAttention 等优化,都需要在内存管理、调度、模型、算子等多个层面联合优化。这要求必须由引擎层统一管理。
我们的实现采用引擎层管理:kv_cache.py 负责分配,main.py 的 generate 循环负责传递。
KVCacheEntry 的粒度:batch 粒度 vs request 粒度?
KVCacheEntry 可以按 batch 粒度 分配,也可以按 request 粒度 分配:
- batch 粒度:整个 batch 共享一个
cached_len,所有 request 同步进退。短 request 浪费 padding,某个 request 结束必须等其他人。 - request 粒度:每个 request 独立管理自己的 cache 和长度,可以动态组合成不同的 batch。这是 Continuous Batching 的基础。
但 request 粒度需要算子的支持——要么逐 request 串行 forward(简单但无法利用 GPU 并行),要么使用变长注意力内核(如 FlashAttention 的 varlen 接口)。
当前版本只支持 Static Batching,因此采用 batch 粒度的 KVCacheEntry。
实现
KVCacheEntry
KVCacheEntry 中的 cached_len 记录已缓存的 token 数量。k_cache / v_cache 的后四个维度,对齐多头注意力计算中 K/V 的形状 [B, H, T, d_k]:
@dataclass
class KVCacheEntry:
# KVCacheEntry is in batch granulity, not request granulity
# q shape: [B, H, T, d_k]
# shape: [L, B, H, W, d_k]
k_cache: torch.Tensor
v_cache: torch.Tensor
cached_len: int = 0
KVCacheEntry 的内存布局上,以最内层的单头为例,k_cache 预分配了 W (W=prompt长度+最大输出长度) 个位置的容量,但当前只有前 cached_len 个位置被填入,剩余的留待后续 decode 步骤使用。
Model.forward
为了支持启动/禁用 KV Cache,Model.forward() 增加了 use_cache 参数。启用时,调用方必须传入为这个 batch 分配的 KVCacheEntry:
class Model(abc.ABC):
@abc.abstractmethod
- def forward(self, input_ids: torch.Tensor, batch_id: int) -> torch.Tensor:
+ def forward(self, input_ids: torch.Tensor, kvcache_entry: Optional[KVCacheEntry], use_cache: bool = True) -> torch.Tensor:
'''
a LLM model.
注意 input_ids 的含义也随之改变:
- 禁用 KV Cache 时:
input_ids是全部 token,包含 prompt 和已生成的 token,每步 concat 追加。 - 启用 KV Cache 时:
input_ids是增量 token,只包含上一步新产生的 token。
Positional Embedding
启用 KV Cache 后,input_ids 只含增量 token。因此不管是绝对位置嵌入(GPT-2),还是相对位置编码(RoPE),input_ids[0] 对应的位置编号都变了——从 0 变成了 $cached_len$,依次类推。
所以计算 Positional Embedding 时,必须加上 offset:
def forward(self, input_ids: torch.Tensor, kvcache_entry: Optional[llm_types.KVCacheEntry], use_cache: bool = True) -> torch.Tensor:
# input_ids: [batch, seq]
- x = self.embed.forward(input_ids)
+ x = self.embed.forward(input_ids, kvcache_entry.cached_len if use_cache else 0)
# x: [batch, seq, d_model]
对于绝对位置嵌入,offset 直接加在位置嵌入查表的索引上:
def forward(self, input_ids: torch.Tensor, offset=0) -> torch.Tensor:
seq_len = input_ids.shape[-1]
x = self.wte_weight[input_ids]
x = x + self.wpe_weight[offset : offset + seq_len, :]
return x
对于 RoPE,offset 同样作用在位置编号的计算上。
Attention:KV Cache 的使用和更新
核心做法是先写入、再读取:把新产生的 K/V 写入 cache 的 cached_len 位置,然后从 cache 的起点开始读取完整的 K/V,用于本次 attention 计算。
这个方式避免了每步的内存分配(torch.cat 会触发分配),是一种预分配内存的 StaticCache 做法,有利于运行的稳定性。虽然切片得到的 K/V 在内存中不完全连续,但对性能损失很小。
def attention(self, x: torch.Tensor, kvcache_entry: Optional[llm_types.KVCacheEntry], use_cache: bool = True) -> torch.Tensor:
seq_len = x.shape[-2]
x = layer_norm(x, weight=self.ln_1_weight, bias=self.ln_1_bias, eps=self.layernorm_eps)
qkv_merged = torch.matmul(x, self.attn_weight) + self.attn_bias
scale = torch.rsqrt(torch.tensor([self.d_model / self.H], dtype=x.dtype, device=x.device))
# split q, k, v
q, k, v = qkv_merged.split(self.d_model, dim=-1)
q = q.reshape((-1, seq_len, self.H, self.d_model // self.H))
q = q.transpose(-2, -3)
k = k.reshape((-1, seq_len, self.H, self.d_model // self.H))
k = k.transpose(-2, -3)
v = v.reshape((-1, seq_len, self.H, self.d_model // self.H))
v = v.transpose(-2, -3)
+ if use_cache:
+ cached_len = kvcache_entry.cached_len
+ # write new k/v into cache
+ kvcache_entry.k_cache[self.layer_id, :, :, cached_len : cached_len + seq_len, :] = k
+ kvcache_entry.v_cache[self.layer_id, :, :, cached_len : cached_len + seq_len, :] = v
+ # read full k/v from cache
+ k = kvcache_entry.k_cache[self.layer_id, :, :, : cached_len + seq_len, :]
+ v = kvcache_entry.v_cache[self.layer_id, :, :, : cached_len + seq_len, :]
+ causal_bias = self.causal_bias[cached_len : cached_len + seq_len, : cached_len + seq_len]
+ else:
+ causal_bias = self.causal_bias[:seq_len, :seq_len]
+
scores = torch.matmul(q, k.transpose(-2, -1)) * scale
# causal mask
- scores += self.causal_bias[:seq_len, :seq_len]
+ scores += causal_bias
Attention:因果掩码
上面的代码还展示了因果掩码的处理。图形化表示:
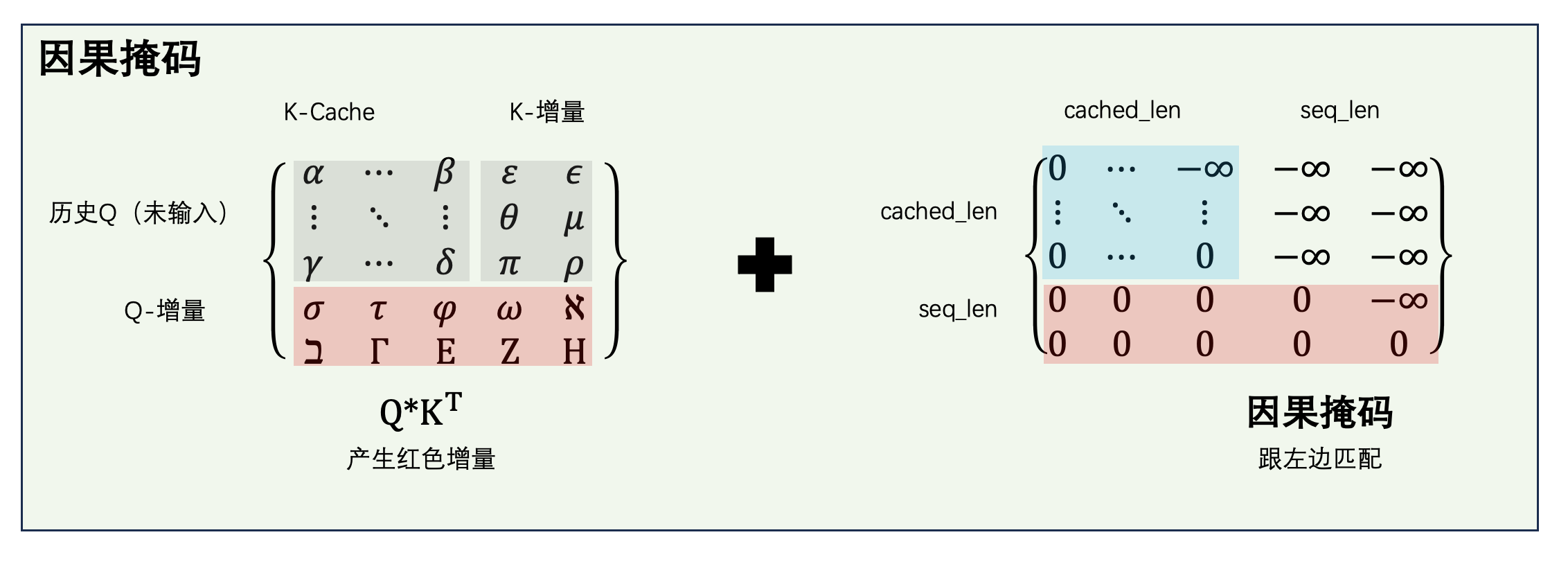
对于增量只有一个 token 的常规 decode 步骤,因果掩码实际上不起作用——因为最后一个 token 可以看到前面所有 token,掩码全是 0。但代码处理了增量有多个 token 的情况(图中增量为 2 个 token)。
$Q K^T$ 的结果是什么形状?Q 只有增量部分,即最后 2 个 token,因此 $Q K^T$ 是一个 [seq_len, cached_len + seq_len] 的非方阵。对应到完整的因果掩码中,就是左图中红色高亮的区域——原始方阵的 [cached_len : cached_len + seq_len, : cached_len + seq_len] 部分。
因此,右侧的因果掩码也要取对应的切片:[cached_len : cached_len + seq_len, : cached_len + seq_len]。
Chunked Prefill
什么时候增量的 token 数量会大于 1?典型场景是 Chunked Prefill:把长 prompt 切成多个片段,依次进行 prefill:
- 第一次 prefill:
input_ids[0:512] - 第二次 prefill:
input_ids[512:1024] - 依次类推
每次 prefill 都是"增量有多个 token 的 decode"步骤。前面描述的因果掩码处理方式,天然就能支持 Chunked Prefill。
结果
在 gpt2-small(L=12, d_model=768, H=12)上的测试结果:
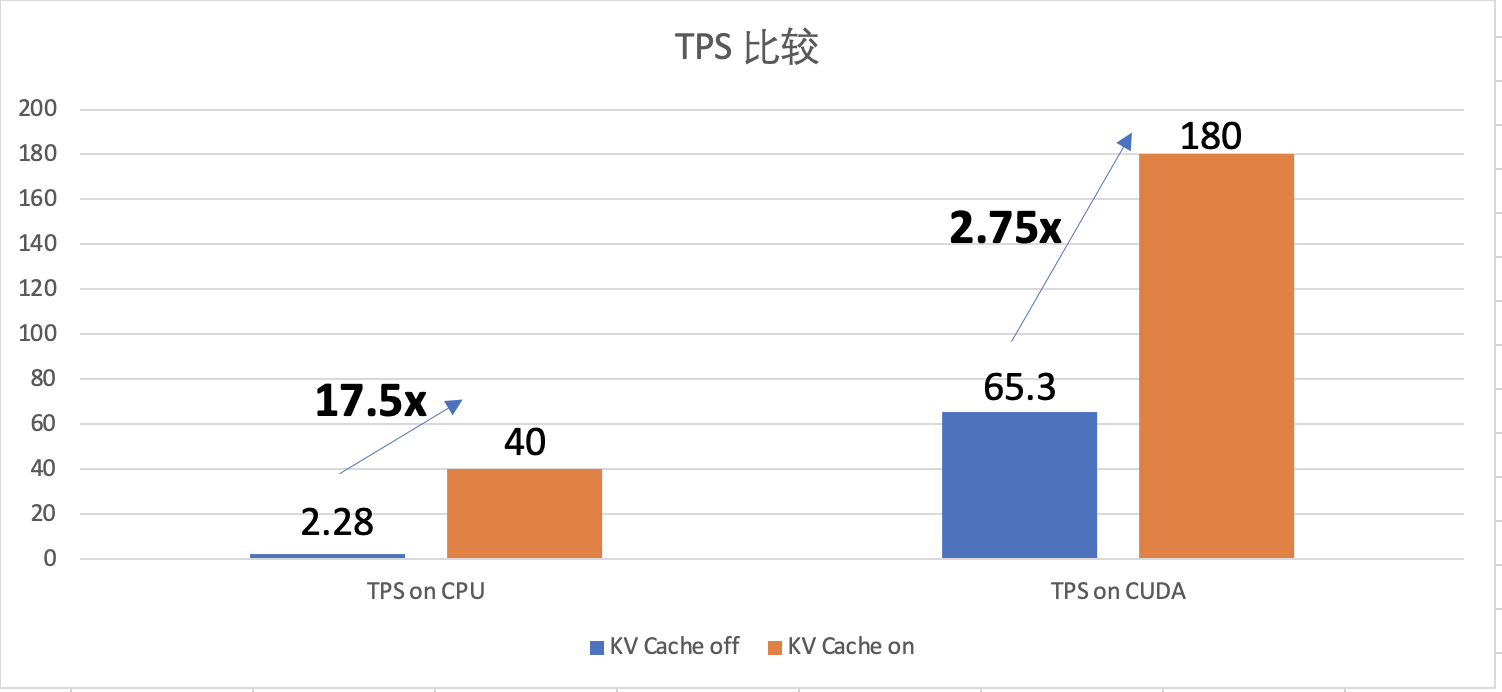
KV Cache 让 decode 阶段的每步时间从 O(T²) 降为 O(T)(其中 T 是当前序列长度)。当生成长度较大时,性能提升尤为显著——生成越往后,无 KV Cache 时的重复计算越严重。
Stay Curious
这个实现展示了 KV Cache 最核心的机制:预分配 cache,写入新 K/V,读取完整 K/V 做 attention。从原理到代码,大约 20 行核心逻辑就能带来数倍的加速。
但我们的实现有两个明显的局限。第一是 Static Batching:batch 中所有 request 必须同步进退,短 request 浪费 padding,一个结束要等全部结束。要支持 Continuous Batching,需要把 cache 粒度从 batch 降到 request,并让算子支持变长序列——要么逐 request 串行 forward(简单但慢),要么使用 FlashAttention 的 varlen 接口(高效但需要 CUDA)。
第二是 内存分配策略:我们预分配了 prompt_len + max_output_len 的容量,生成越短浪费越大。vLLM 的 PagedAttention 借鉴了操作系统的虚拟内存思想,把 cache 切分成固定大小的 block,按需分配和回收,大幅降低了显存碎片。
从 KV Cache 出发,下一步可以探索 Chunked Prefill 的调度、Paged KV Cache 的内存管理,以及投机解码(Speculative Decoding)中 cache 的回滚机制。每一步都是在"空间"和"时间"之间寻找更好的平衡。