[模型推理] Inference From Scratch: KV Cache - Part1 / 推理中的 KV Cache - 原理篇
文章含 AI 量:< 10%。AI 主要负责润色,以及补充了 Prefill 和 Decode 的阐述。
代码含 AI 量:< 5%。
代码面前,了无秘密。只有亲手重写一遍,才能看清藏在细节里的魔鬼。
代码:https://github.com/solofox/gpt2,branch:kvcache。
这篇讲 KV Cache 的原理,下篇讲实现。
KV Cache
KV Cache 是大模型推理中最核心的优化手段,本质是"以空间换时间"——通过缓存历史 token 的 Key/Value 向量,避免每一步重新计算,从而大幅提升 TPS(Tokens Per Second)。有了 KV Cache,推理过程才有了 Prefill 和 Decode 两个阶段的区分,它是后续几乎所有高级优化的基础:
- Continuous Batching
- Chunked Prefill
- PagedAttention
- RadixAttention
- PD 分离
- Hybrid KV Cache
不懂 KV Cache,大模型的优化寸步难行。
KV Cache 推导
抽丝剥茧,从输出往前推导——KV Cache 的原理是什么?为什么有 K Cache 和 V Cache,却没有 Q Cache?
继续参考 GPT-2 的模型架构,下面这张图标注了每一步运算的输出形状:
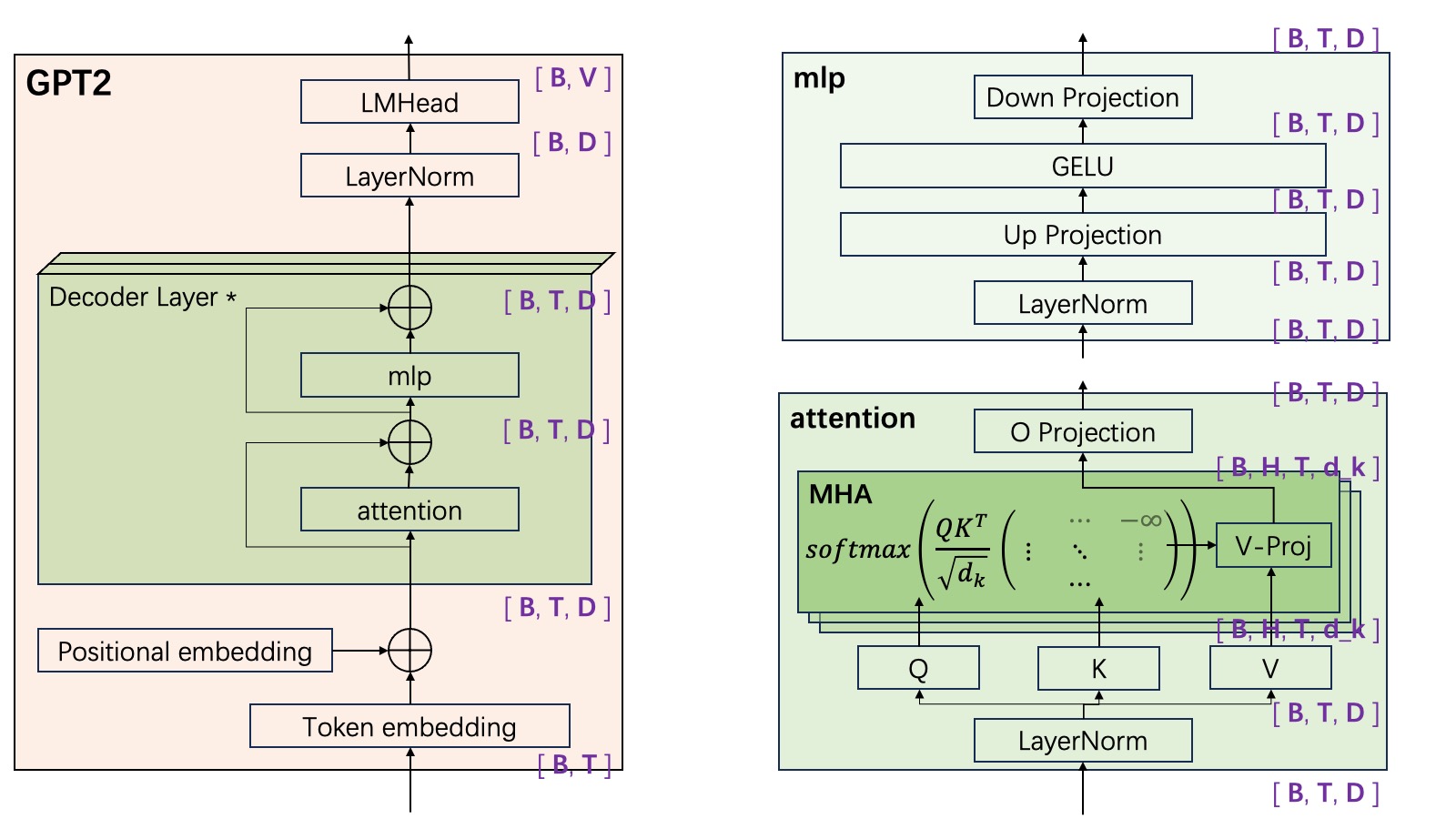
以下超参数采用统一缩写:
| 符号 | 含义 |
|---|---|
| $B$ | Batch Size,批大小 |
| $H$ | Head Number,注意力头数 |
| $T$ | Sequence Length,序列长度(单个请求的 token 数) |
| $L$ | Layer Number,Decoder 层数 |
| $d_{\text{model}}$ | Embedding 维度 |
| $d_k$ | 单头向量维度,$d_k = d_v = d_{\text{model}} / H$ |
基础
先说结论:自回归模型做 next-token prediction 时,最终输出的最后一行才是我们要用的数据。所以分析的核心是:每一步操作中,输出的最后一行到底由输入的哪些部分决定?
将模型中的操作分为三类:矩阵乘法、Row-wise 操作、Element-wise 操作,逐一看清它们的依赖关系。
矩阵乘法
模型中,FFN、x @ W_q、x @ W_k、x @ W_v、scores @ V 等等都是矩阵乘法。
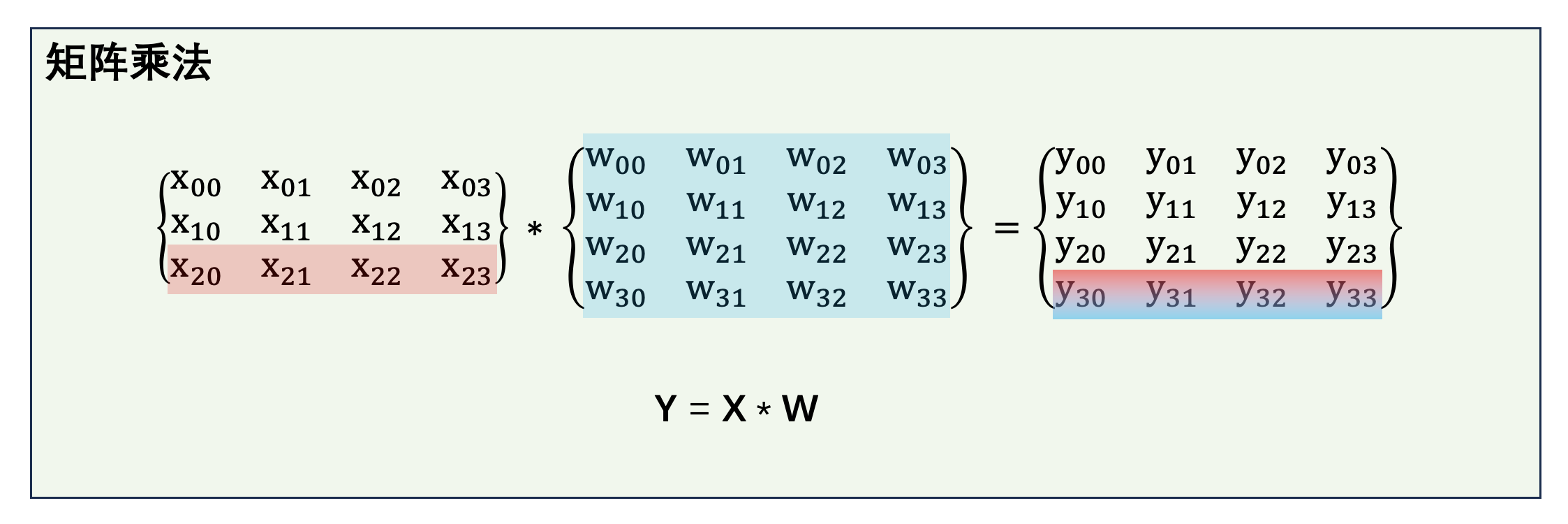
规律很直观:输出的最后一行 = 左操作数的最后一行 × 右操作数的整体。
特殊情况:如果右操作数是模型权重(定值),结论就简化为——输出的最后一行只依赖输入的最后一行。
Row-wise 操作
softmax、LayerNorm 都是 Row-wise 操作:每个 token 的归一化只在自己的那行内进行,不跨行传播。

结论:输出的最后一行只依赖输入的最后一行。
Element-wise 操作
激活函数(如 GELU)、残差加法等都是 Element-wise 操作,按元素独立计算。
结论:输出的最后一行只依赖输入的最后一行。
三类操作的共同结论:只要右操作数是定值,或者操作是逐行/逐元素的,输出的最后一行都只依赖输入的最后一行。这是整个分析的地基,后面每一步都建立在它之上。
倒数第一步:LMHead
LMHead 的输出形状:[B, V],第 1 维上是每个请求在不同 token 上的 logits 分布。
LMHead 的输入形状:[B, d_model]——每个 token 位置的一个语义向量。
LMHead 的操作是 output = input @ W,形状是 [B, d_model] × [d_model, V] → [B, V]。
这个 [B, d_model] 的输入从哪里来?
倒数第二步:Output LayerNorm
Output LayerNorm 的输出:[B, d_model],含义同上。
Output LayerNorm 的输入:[B, d_model],每个 token 位置的一个语义向量。
LayerNorm 是 Row-wise 操作,它的输入 [B, d_model] 又从哪来?
倒数第三步:维度不匹配,藏着关键一步
倒数第三步难道是 Decoder 的最后一层?来对照一下形状:Decoder 层的输出是 [B, T, d_model],而 Output LayerNorm 的输入是 [B, d_model]——维度差了一截。怎么回事?
这就是自回归模型的关键一步:我们只用 Decoder 层的最后一个位置来预测下一个 token。
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
# input_ids: [B, T]
x = self.embed.forward(input_ids)
# x: [B, T, d_model]
for decoder in self.decoders:
x = decoder.forward(x)
# x: [B, T, d_model]
x = layer_norm(x, weight=self.ln_f_weight, bias=self.ln_f_bias, eps=self.layernorm_eps)
# the next-token prediction only needs the last item in each sample
x = x[:, -1, :]
# x: [B, d_model]
logits: torch.Tensor = self.lm_head.forward(x)
# logits: [B, vocab_size]
return logits
x = x[:, -1, :] 就是这一刀:把 [B, T, d_model] 压成 [B, d_model],只保留最后一个位置的语义向量,喂给 LayerNorm 和 LMHead。
所以后面每一步的分析,都聚焦于:这一行的数据在计算时依赖了哪些位置的信息?
倒数第四步:Decoder Layer
最关键的一步。我们从输出端 [B, -1, d_model] 出发,逆向追踪 Decoder Layer 的数据来源。
Residual Connection
MLP 和 Attention 各自都有残差连接。残差加法是 Element-wise 操作,这意味着:残差连接的输出 [B, -1, d_model] 同时依赖 MLP / Attention 各自的输出和输入,我们需要分别沿着输入和输出路径找到它们的依赖。
MLP
沿着 MLP 的数据流逆向追踪,标出每个操作的依赖:
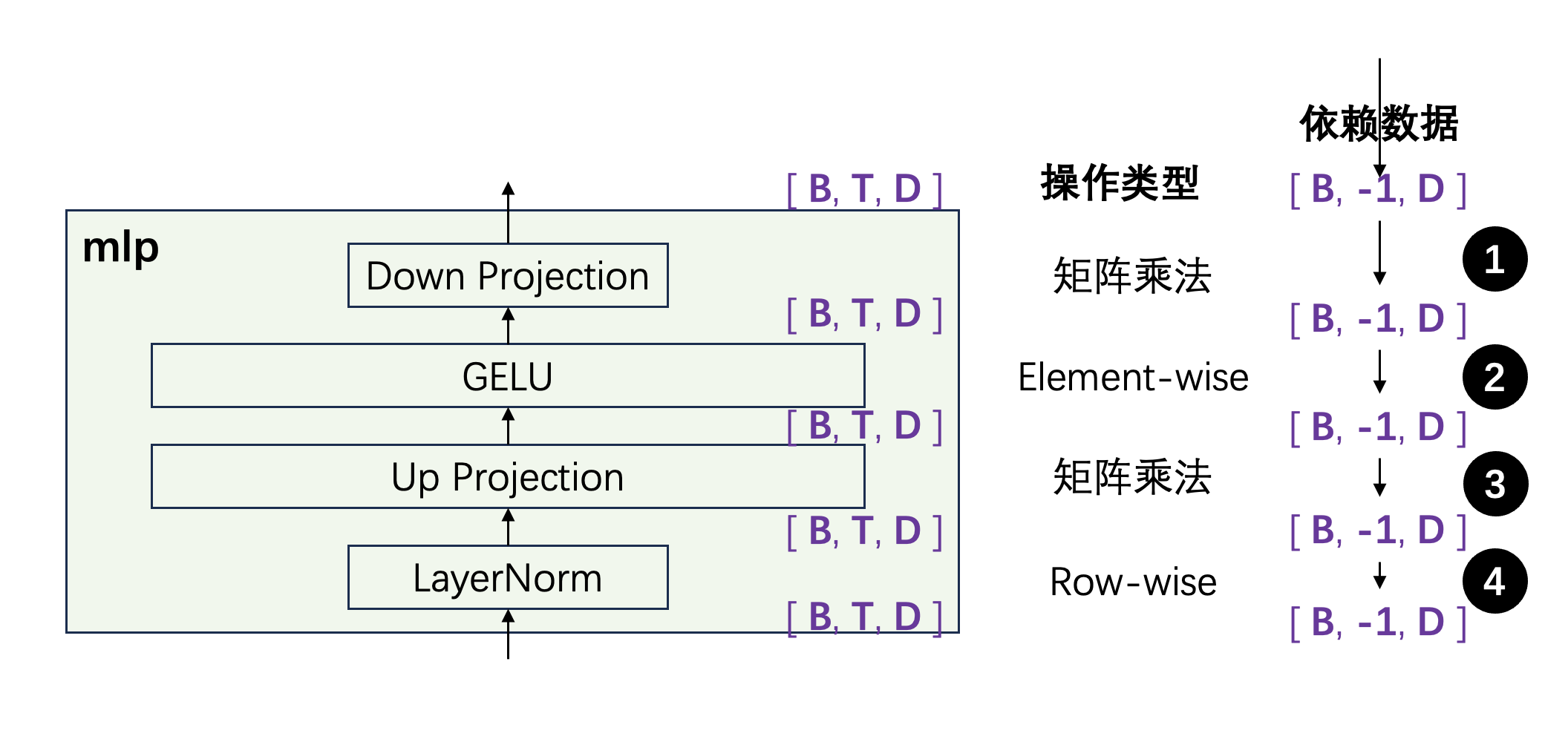
已知 MLP 层的输出(残差加法后)需要 [B, -1, d_model],逆向推导:
- Down Projection(矩阵乘法):右操作数是模型权重(定值),依赖左操作数的最后一行。
- GELU(Element-wise):依赖输入的最后一行。
- Up Projection(矩阵乘法):同上,依赖左操作数的最后一行。
- LayerNorm(Row-wise):依赖输入的最后一行。
结合残差连接,MLP 整体只需要 Attention 输出的 [B, -1, d_model]。
Attention
Attention 是 Decoder 的核心,也是分析最复杂的一步。画出数据依赖图:
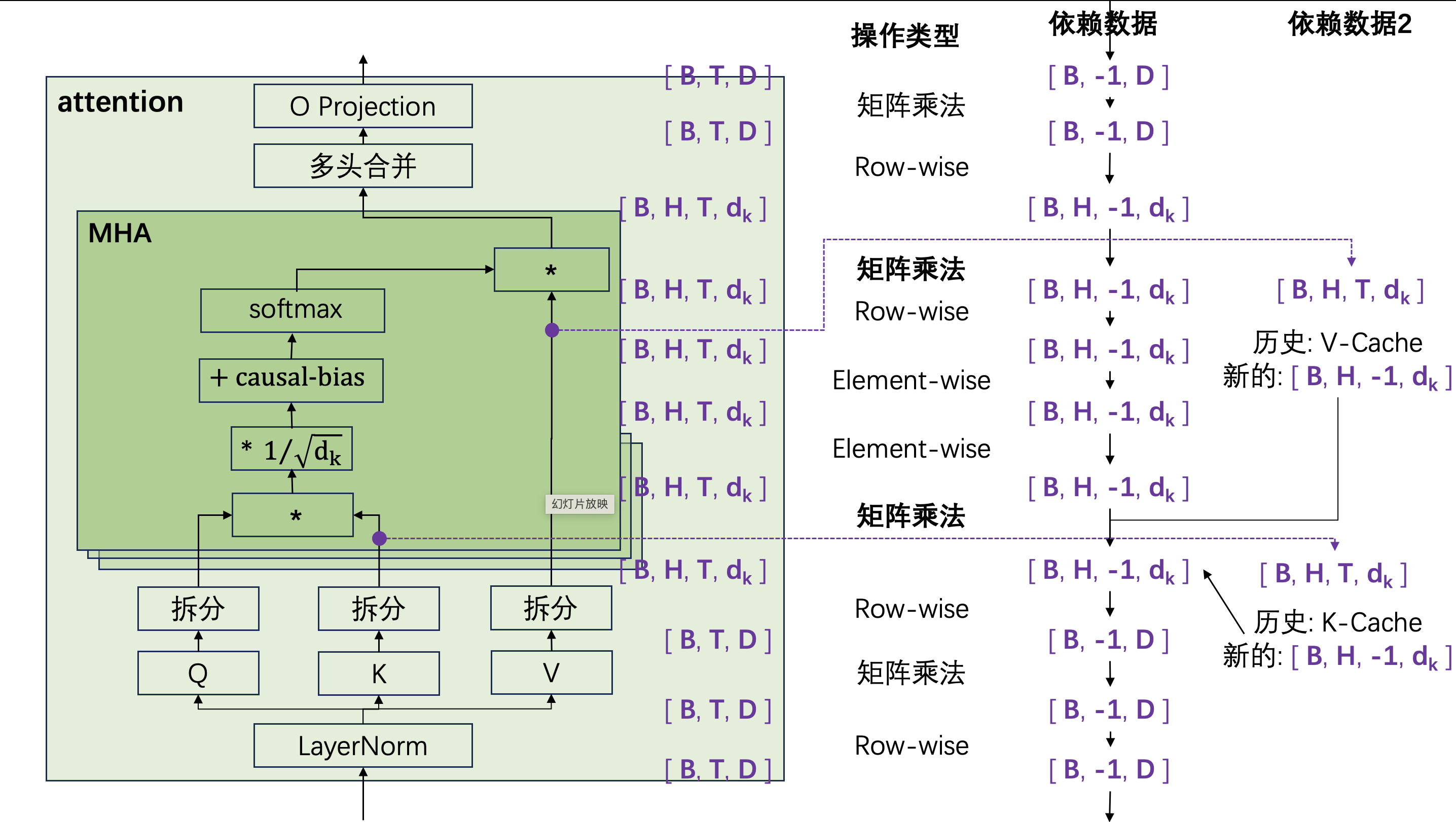
下面重点分析几个特殊操作:
1. 多头拆分(Split)与多头合并(Merge)
它们的本质是 reshape + transpose,不改变数据的"位置独立性"——操作前后,某个位置(某个 T)的数据只依赖该位置自身的输入,不跨位置混合信息。所以它们的依赖分析方式和 Row-wise 操作一致。
以多头拆分为例:
[B, T, d_model]
→ reshape → [B, T, H, d_k]
→ transpose → [B, H, T, d_k]
输出的最后一行 [B, H, -1, d_k] 完全来自输入的 [B, -1, d_model]。多头合并是它的反操作,同理。
2. Attention Scores:$Q K^T$
Attention Scores 的计算形状是 [B, H, T, d_k] × [B, H, T, d_k]ᵀ → [B, H, T, T]。我们只关心其中最后一行——即最后一个 query 位置对所有 key 位置的相似度分数 [B, H, -1, T]。
这一行的数据依赖有两个来源:
- 左操作数 Q 的最后一行:
[B, H, -1, d_k](当前 token 的 query) - 右操作数 K 的全部:
[B, H, T, d_k](所有历史 + 当前 token 的 key)
这就是 K Cache 发挥作用的地方。 K Cache 存储了之前步骤已经算过的 K 向量 [B, H, 0 : T-1, d_k]。所以每算一个新 token,K 只需要算出这一个新位置的 k 向量 [B, H, -1, d_k],和 K Cache 拼起来,就得到了完整的 K。
3. Attention Output:$\text{scores} \times V$
同理。scores 的最后一行 [B, H, -1, T] 需要和 V 的全部 [B, H, T, d_k] 相乘。V Cache 存储历史 V 向量,新 token 只需算出新位置的 v 向量,与 V Cache 合并后参与计算。
总结:Q 为什么不需要缓存?
从上面的分析可以得出关键结论:计算 attention scores 的最后一行时,需要的 Q 永远只是当前 token 的 q 向量,不需要历史的 Q。而 K 和 V 需要全部历史位置的向量。这就是为什么我们只缓存 K 和 V,而不缓存 Q。
把 attention 和 MLP 的残差连接合在一起看,整个 Decoder Layer 的输出 [B, -1, d_model] 最终只依赖前一个模块(上一层 Decoder,或者 Embedding 层)输出的 [B, -1, d_model]。
倒数第五步:Token Embedding & Positional Embedding
这两个都是 Row-wise 操作,反向推导:它们的输出 [B, -1, d_model] 只依赖 forward 输入的最后一个 token 位置,即 [B, -1](索引 T−1 处的 token id)。
Prefill & Decode
到这里,数据依赖的全貌已经清晰了。
输入侧:生成新 token 只需要最后一个 token id,即 [B, -1]。
计算侧:Attention 中的 $Q K^T$ 和 $\text{scores} \times V$ 却依赖完整的 K/V 矩阵(所有历史 token 都要参与),而不能只靠最后一个 token。
这个不对称性,把推理过程天然地切割成了两个阶段:
- Prefill:KV Cache 为空,将整个 prompt(共 T 个 token)送入模型,完整走一遍前向计算,得到第一个输出 token。在这个过程中,把每个 Decoder Layer 中算出来的 K、V 矩阵存入 KV Cache。Prefill 的含义是"填充"——把缓存填满。
- Decode:KV Cache 已有历史数据。每一步只送入一个新 token(
[B, 1])作为输入,从 KV Cache 中读出历史的 K/V,与新 token 算出的 K/V 合并成完整的 K/V,做 Attention 计算,产出下一个 token。同时把新算出的 K/V 追加到 Cache 中,为下一步使用。Decode 的含义是"解码"——每步解码出一个新 token。
正是 Prefill 阶段的全量输入,让后续 Decode 阶段可以"只喂一个新 token"而依然获得正确结果。KV Cache 的存在,让原本每一步 O(T²) 的 Attention 计算降为 O(T)——这是生成速度提升的核心来源。
Stay curious
推导完成。下篇我们亲手实现它。